How I Built an AI Resume Engine That Treats Your Career Like a Database
Most of my side projects start the same way: something annoys me long enough that fixing it feels easier than living with it. This time the annoyance was my own resume.
The Problem: A File That Fights You
You probably know the ritual. You open last month's resume, duplicate it, and name the copy something hopeful like resume_v7_final_REAL.pdf. You rewrite a few bullets to match the job posting, send it off, and do the whole thing again next week.
I kept that up for about six months. By the end I had fourteen resumes that all disagreed with each other. A typo I'd fixed in one was still alive in the others. A project description I'd spent an evening sharpening lived in a file I could no longer find. When a recruiter mentioned "the resume you sent," I often had no idea which one they meant.
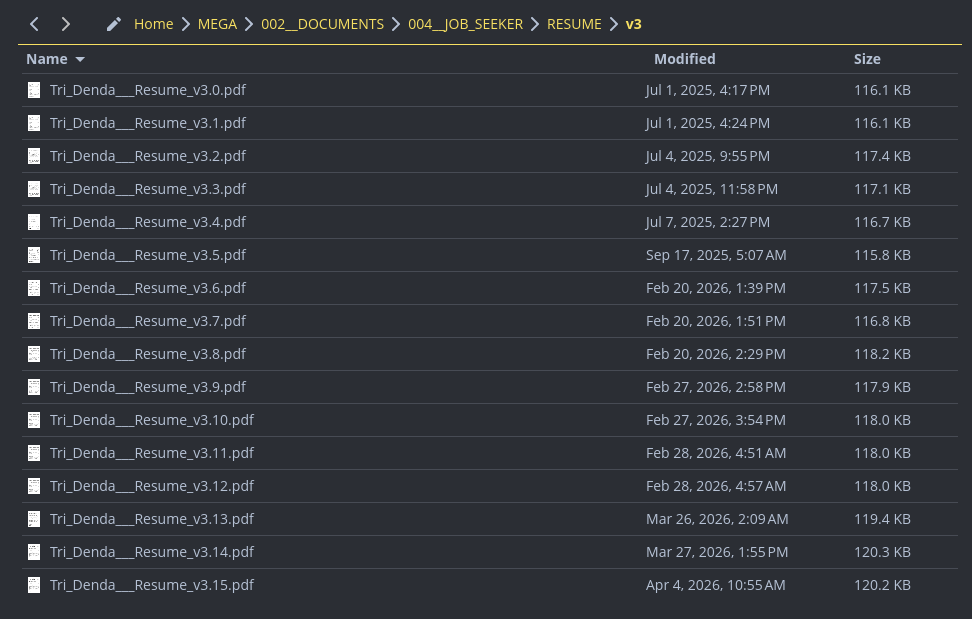
That screenshot isn't a bit. It was my real folder: v3.0 through v3.15, sixteen files spread across a year, each one a couple of kilobytes off from its neighbors and none of them obviously the canonical one.
For a while I figured I was just messy. Then it clicked. I'd seen this exact problem hundreds of times, only in code.
A resume quietly mixes two jobs into one file. One job is the data: where you worked, what you shipped, the dates. The other is the presentation: which of those facts to surface, in what order, and how to phrase them for a particular reader. Every application wants a different presentation. The data underneath barely moves.
Glue those two things into a single .docx and you get exactly what you'd expect. Every cosmetic edit can quietly damage the facts, and every real update has to be re-typed into a dozen copies by hand. That isn't a discipline problem. It's an architecture problem, and engineering settled it a long time ago. We call it separation of concerns.
So I built BeautifulCV to drag that idea into resume land.
The Process: Build It Like a System, Not a Document
I approached it the way I'd approach any backend, by asking one question first. What is the source of truth, and what gets derived from it?
That source of truth became the Master Vault: one structured, canonical record of my whole career. Every job, project, skill, certification, and award goes in once, with no length limit. The Vault isn't a resume. It's the database that every resume gets generated from, a superset of anything I'd ever put on a page.
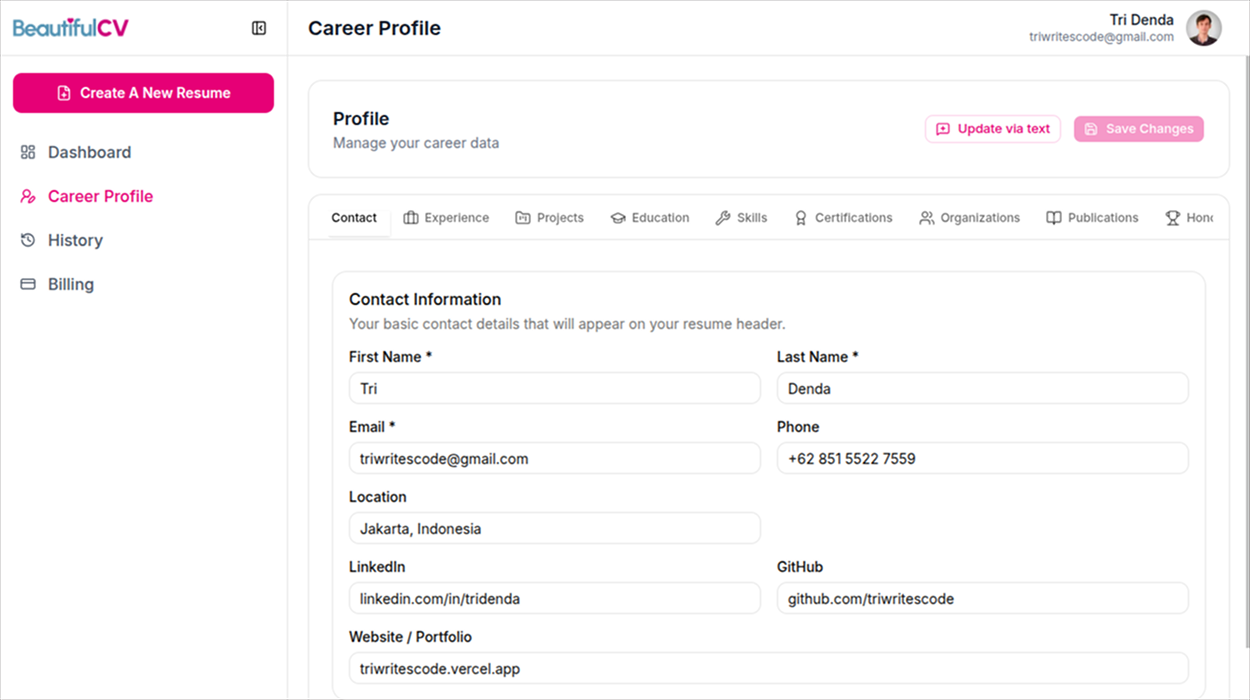
For this to work, keeping the Vault current had to be effortless. If it felt like a chore, I knew I'd let it rot. So alongside the usual tabbed forms, I can also just talk to it. I paste a sentence like "joined Tokopedia as Senior Frontend Engineer in April 2026, led the jQuery to React migration," and Claude pulls out the structure, tightens the bullets, and checks it against what's already there. If the new text contradicts something, it asks before touching a field. Updating my career turns into one sentence instead of a form.
Once the Vault exists, a resume stops being a file and starts behaving like a query. Hand it a job, and it pulls the most relevant slice of my history, arranges it for that reader, and renders it. Fix a fact in the Vault and every resume I generate afterward is already correct. I never edit the same fact in two places again.
The genuinely hard part was that query engine. "Pick the parts that matter and rephrase them for this job" is the kind of fuzzy judgment that's painful to express as if statements but comes naturally to a language model. So I stopped trying to write the judgment by hand and instead built a pipeline of AI stages, each with typed inputs and outputs and exactly one job to do.
Here's what each stage does:
- Parse the job description. The raw posting goes in and Claude hands back a structured object: must-have skills, nice-to-haves, seniority signals, tone. Messy text becomes a clean schema.
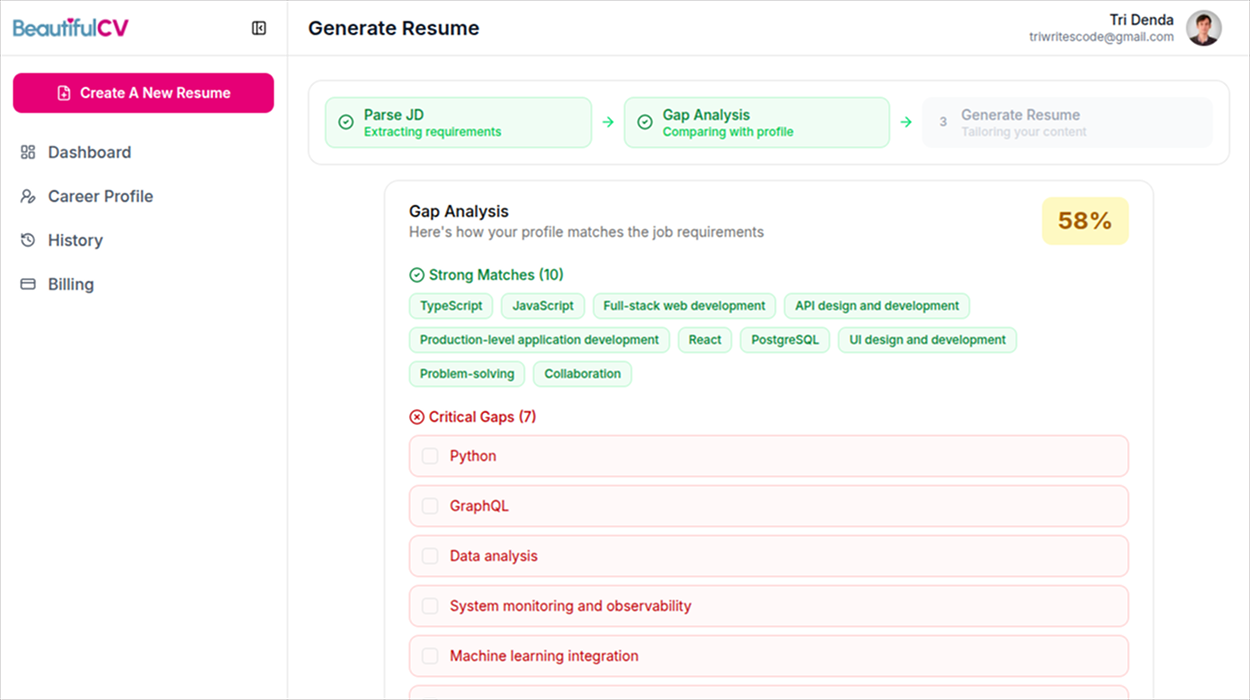
- Run a gap analysis. Now it compares what the role wants against what's actually in my Vault. If something important is missing, it tells me up front, so I can either add real experience or decide to skip it on purpose. Nothing gets invented to fill the hole.
- Reframe the content. The engine scores each Vault entry for relevance, keeps the strongest ones, and reorders the sections to suit the role. Leadership leads for a manager posting; skills lead for an individual contributor one. Then it rewrites the bullets in the job's own vocabulary, without inventing anything. Staying factually accurate is a hard constraint, not a suggestion.
- Review in a glass box. Every rewrite shows up with the reasoning attached, so I can see why a line changed and override it on the spot. The model suggests, but I'm the one who signs off.
- Draft a matching cover letter. Once a resume version exists, one click writes a cover letter from the same Vault data and the same parsed posting. Because it shares a source with the resume, it can't drift off and tell a different story. A quick note like "mention my open-source work" nudges the tone when I want it.
Building that pipeline taught me the lesson I keep relearning. A demo is easy. A system has to survive real use, and with AI in the loop, real use bites harder than usual.
The sharpest surprise was realizing that cost is a security boundary. Every Claude call burns tokens, and tokens cost money, so an unguarded endpoint isn't just untidy. It's a denial-of-wallet attack sitting there waiting for someone to find it. I put per-user limits on every AI endpoint, capped how much input each call accepts, and made the server fetch the canonical Vault from the database itself instead of trusting whatever the browser sends. The client can't pad the prompt, and it can't pad the bill.
I also tripped over a textbook race condition in my own usage counter. "Read the count, check the limit, write count plus one" reads fine until five requests land at the same instant. All five read the same number, all five pass the check, all five write the same increment, and the limit quietly does nothing. The fix was to move the whole operation into a single atomic database increment inside a transaction. While I was there, I reordered it so a credit is only spent after a generation actually succeeds. If a stream dies halfway through, you don't pay for the failure.
Everything else is plain defense in depth. Row-level security so the database itself keeps one user's data away from another's. Secrets that never leave the server. Private per-user storage for exported PDFs. Webhook signatures verified in constant time. For speed, the pipeline streams its output and leans on prompt caching so repeated tokens don't cost full price.
If you like knowing what's under the hood: it runs on Next.js 16 and React 19, with end-to-end TypeScript and Zod guarding every boundary. Claude drives the AI work through the Anthropic SDK, Supabase handles Postgres, auth, and storage, and @react-pdf/renderer produces output that stays selectable, linkable, and friendly to applicant tracking systems.
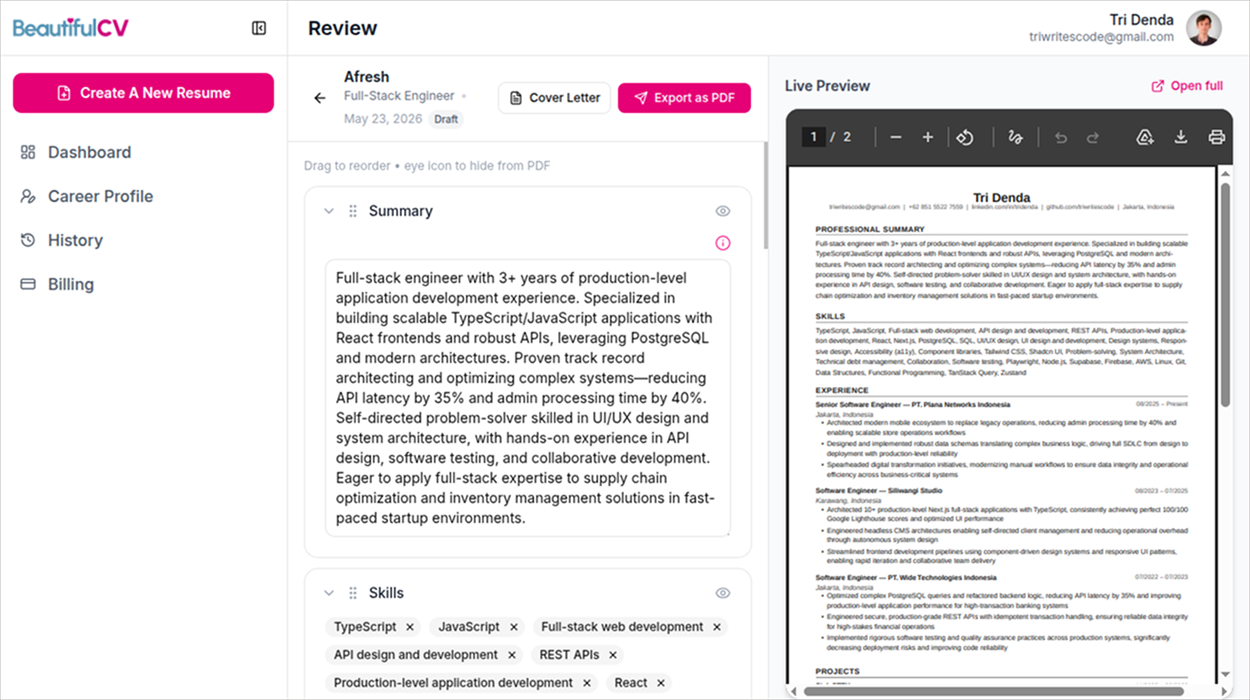
The Solution: One Profile, Endless Resumes
What I ended up with is the workflow I wanted from the start. I keep one Vault current. When a job catches my eye, I paste the description, watch a tailored draft appear in seconds, read the reasoning, fix anything that feels off, spin up a matching cover letter, and export a clean PDF. Each one is versioned and tagged with the company, so I always know what I sent and to whom.
No more resume_v7_final_REAL.pdf. No more versions quietly disagreeing with each other. One source of truth, and as many tailored resumes as there are jobs worth chasing.
![]()
Same career, same year, but now every resume lives in one place. Each one carries its company and role and moves through the pipeline from Exported to Applied to Interviewing. The folder of mystery PDFs is gone, and in its place is a system that actually remembers what I sent and where each application stands.
Honestly, though, the resume is almost a footnote now. What stuck with me was the reminder of what this work is really about. You take a messy, frustrating human problem, find the clean system hiding inside it, and then defend that system against the unglamorous stuff that only shows up once real people start using it: cost, concurrency, abuse. That instinct outlives any single project.
If you build products where correctness, AI, and careful engineering all matter, I'd love to compare notes. Come say hello on LinkedIn.
Want to see the whole loop end to end? Here's a short walkthrough: